特斯拉介绍,D1芯片可以提供22.6 TFLOPS的单精度浮点运算性能,BF16/CFP8的峰值算力达到了362 TFLOPS,热设计功耗(TDP)不超过400W。对AI训练来说,可扩展性非常重要,因此通过带宽为10 TB/s的“延迟交换结构”在各个方向进行互连。
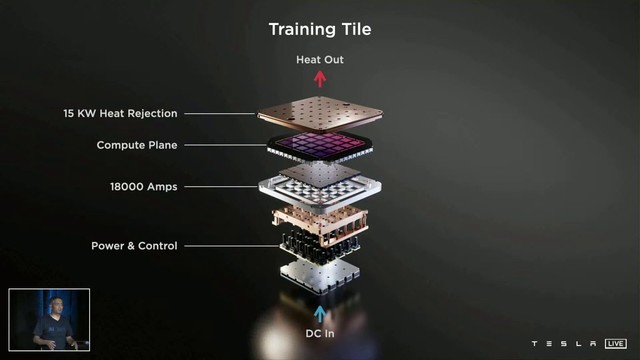
为了支撑AI训练的扩展性,它的互连带宽非常惊人,最高可达10TB/s,由多达576个通道组成,每个通道的带宽都有112Gbps。而实现这一切,热设计功耗仅为400W。

据悉,将包含3000个D1芯片的120个训练模块可以组成ExaPOD,能够提供超过100万个训练节点,BF16/CFP8的峰值算力达到1.1 ExaFLOPS。